数据类型
某些聚合函数可以作用于所有数据类型,例如COUNT;而某些聚合函数只能作用于特点数据类型,例如SUM只能作用于数值类型。某些数据看起来是数值,但是很可能是以VARCHAR形式存储的。这就涉及到了数据类型的转换。可以采用以下两种形式。
CAST(column_name AS integer)
column_name::integer我们注意到在Date数据类型中,年是放在最前面的,采用YYYY-MM-DD的格式。这是为了我们在排序的时候更加方便。即便有些日期是以String形式存储的,按照这个格式进行排序,依然不会出错。
在进行日期计算的时候,可以使用Interval函数进行加工,例如
company.founded_date <= company.bankruptcy_date + INTERVAL '5 years'字符串函数
截断字符串
LEFT(string, number of characters)
RIGHT(string, number of characters)
SUBSTR(string, starting position, length)拼接字符串
CONCAT函数将不同字符串进行拼接,括号内字符串个数是任意的。我们也可以使用’||’进行拼接。
CONCAT(str1, str2, str3, ...)
str1 || str2 || str3取长度
LENGTH(string)修剪
将字符串首尾两段某些字符删除掉。第一个参数填写需要去除的位置,’leading’、’trailing’、’both’分别代表只删除前面/后面/两端的字符。第二个参数填写需要被去掉的字符。第三个参数填写字段。
TRIM(both '()' FROM location)位置
找出某个子串在字段中的起始位置,被查找的子串区分大小写。有以下两种写法,目前mysql支持第一种写法。
SELECT name, POSITION('o' IN name)
SELECT name, STRPOS(name, 'o') 大小写转换
UPPER(string)
LOWER(string)时间
可以使用EXTRACT函数提取有用的时间段。
DATE_TRUNC函数将日期四舍五入到指定的精度。显示的值是该时间段的第一个值。因此,当DATE_TRUNC by year时,该年份的任何值都会被列出为该年份的1月1日。
SELECT cleaned_date,
EXTRACT('year' FROM cleaned_date) AS year,
EXTRACT('month' FROM cleaned_date) AS month,
EXTRACT('day' FROM cleaned_date) AS day,
EXTRACT('hour' FROM cleaned_date) AS hour,
EXTRACT('minute' FROM cleaned_date) AS minute,
EXTRACT('second' FROM cleaned_date) AS second,
EXTRACT('decade' FROM cleaned_date) AS decade,
EXTRACT('dow' FROM cleaned_date) AS day_of_week
FROM criminals;
-- 选择时区
SELECT CURRENT_TIME AS time,
CURRENT_TIME AT TIME ZONE 'PST' AS time_pst;填充
使用COALESCE函数对空值进行填充。
SELECT id, name, COALESCE(descript, 'No Description')
FROM medicine;子查询
子查询必须具有名称,这些名称会在括号后添加,就像在普通表中添加别名一样。如果嵌套许多子查询,不需要一直缩进到括号以内,仅缩进两个左右的空格即可。
多阶段聚合
我们需要的查询结果需要经历多次聚合,则每一次聚合需要采用一层子查询。例如,我们想知道平均每个月事故发生的总量:首先对每天的数据进行聚合,第二步再取平均值。
SELECT MONTH(sub.date), AVG(sub.counts) AS avg_per_month
FROM (
SELECT i.date, COUNT(*) AS counts
FROM incidents AS i
GROUP BY i.date
) sub
GROUP BY MONTH(sub.date)
ORDER BY MONTH(sub.date); 条件逻辑中的子查询
在条件逻辑中使用子查询,经常会搭配MIN或者MAX函数使用。如果子查询会返回多个查询结果,则前面只能使用IN。
SELECT * FROM incidents i
WHERE i.date = (
SELECT MIN(date)
FROM incidents
);请注意,在条件语句中编写子查询时,不应包含别名。这是因为子查询被视为单个值(或IN情况下的一组值),而不是一个表。
联接子查询
我们可以联接一个与外部查询命中相同表的子查询,而不是在WHERE子句中进行过滤。
SELECT i.*, sub.date, sub.counts FROM incidents i
WHERE incidents JOIN (
SELECT date, COUNT(*) counts
FROM incidents
GROUP BY date
) sub
ON i.date = sub.date
ORDER BY sub.counts DESC;也会经常搭配UNION使用。
SELECT COUNT(*) AS total_rows
FROM (
SELECT * FROM investments_part1
UNION ALL
SELECT * FROM investments_part2
) sub窗口函数
窗口函数跨一组与当前行相关的表行执行计算。这相当于可以使用聚合函数完成的计算类型。但是,与常规聚合函数不同,使用窗口函数不会导致不同单独的行被分组之后成为单个输出行,而是保持行的独立标识。在后台,窗口功能可以访问的不只有查询结果的当前行。
接下来,我们使用一个例子进行讲解。数据来源于Capital bike公司的公用数据。这里有一个我清理过后的版本:数据。
建表使用语句,
CREATE TABLE `biking_records` (
`Duration` INT(11) NULL DEFAULT NULL,
`Start_time` DATETIME NULL DEFAULT NULL,
`End_time` DATETIME NULL DEFAULT NULL,
`Start_station` VARCHAR(200) NULL DEFAULT NULL,
`End_station` VARCHAR(200) NULL DEFAULT NULL,
`Bike_id` VARCHAR(50) NULL DEFAULT NULL,
`Member_type` VARCHAR(20) NULL DEFAULT NULL
)
ENGINE=InnoDB
;建表之后,将csv文件导入。
我们使用的案例sql语句见下,
SELECT duration, SUM(duration) OVER (ORDER BY start_time) AS running_total
FROM biking_records;语法
注意,我们不能在同一个查询中使用窗口函数和聚合函数。更具体地说,是不能在GROUP BY子句中包含窗口函数。
如果想将范围从整个数据集缩小到独立组内的数据集,我们可以使用PARTITION。例如下面这个查询,根据起始站对查询进行分组和排序,逐渐累加骑行时间。在同一个起始站的每个值中,按照起始时间排序。
SELECT start_station, duration,
SUM(duration) OVER (PARTITION BY start_station ORDER BY start_time)
AS running_total
FROM biking_records
WHERE start_time < '2012-01-08'如果我们将ORDER BY start_time删除,我们会发现每个起始站的running_total值都变成一样的了,即该起始站的duration的总合。
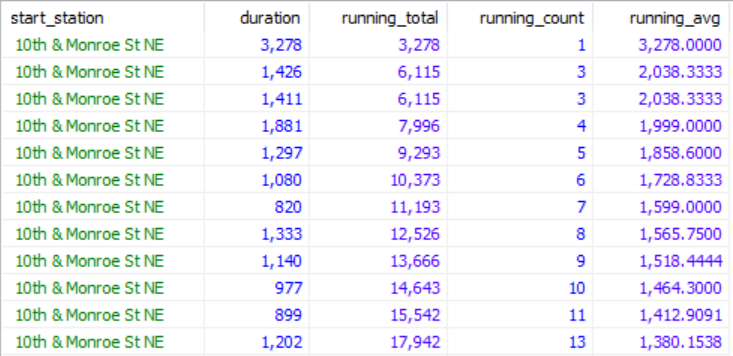
我们再用一个例子来熟悉一下。
SELECT start_station, duration,
SUM(duration) OVER (PARTITION BY start_station ORDER BY start_time) AS running_total,
COUNT(duration) OVER (PARTITION BY start_station ORDER BY start_time) AS running_count,
AVG(duration) OVER (PARTITION BY start_station ORDER BY start_time) AS running_avg
FROM biking_records;效果如下(只是返回结果最前面一部分)。
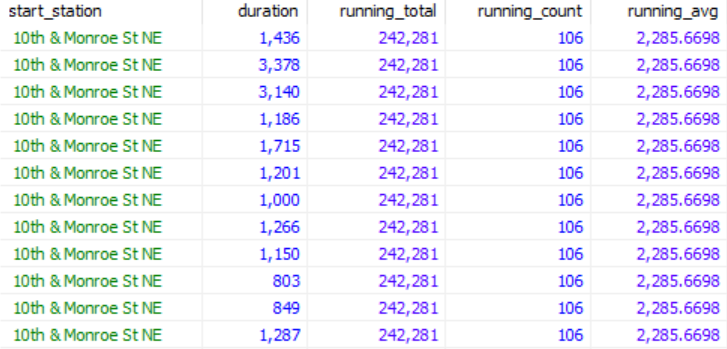
如果将例子中的ORDER BY全部去掉,产生的效果如下。
标记行号函数
ROW_NUMBER()显示给定行的编号,从1开始。如果配合PARTITION BY使用,则会在每个区域内重新开始编号。括号内即便没有PARTITION BY也必须有ORDER BY子句。
该函数在mysql 8.0之前无法使用。
SELECT start_station, start_time, duration,
ROW_NUMBER() OVER (PARTITION BY start_station ORDER BY start_time) AS row_number
FROM biking_records;排名函数
RANK()函数和ROW_NUMBER()其实非常类似。唯一的区别是在对于ORDER BY子句出现并列情况的处理。比如上面的查询对于start_time进行排序,如果两条记录start_time相同,那么两条记录ROW_NUMBER()并不相同(具有唯一性),而RANK()则会返回一样的值(允许排名相同)。
需要注意的是RANK()函数严格遵循排名算法,即假设最开始的两条记录并列,则第三条记录的排名为3。换言之,数据中将不存在排名为2的记录。如果我们不希望这种情况发生(即不跳过任何排名数字),可以使用DENSE_RANK()函数。
分位数函数
NTILE()函数可以知道当前记录在总体情况中的分位数。不过该函数使用频率并不高。
SELECT start_station, duration,
NTILE(4) OVER (PARTITION BY start_station ORDER BY duration) as quartile,
NTILE(100) OVER (PARTITION BY start_station ORDER BY duration) as percentile
FROM biking_records
ORDER BY start_station, duration;临近记录比较函数
经常有需求是将当前行与前一行或后一行进行比较。LAG()函数可以与前面的行进行比较,LEAD()函数可以与后面的行进行比较。
例如,我们想知道两条骑行记录的持续时间之间的差值,可以使用如下查询。
SELECT start_station, duration,
duration - LAG(duration, 1) OVER(PARTITION BY start_station ORDER BY duration) AS difference
FROM biking_records
ORDER BY start_station, duration;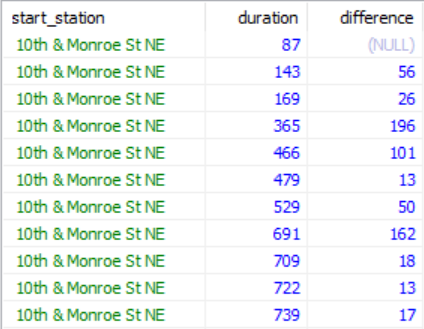
从上图可以发现,因为第一行之前并没有记录,所以默认值是NULL,则在第一行的difference列显示的也是NULL。在实际查询中,我们可以根据需求进行保留或者通过以在外面包装一层查询的方式去除。
窗口别名
当多个窗口函数需要用到相同条件的时候,我们可以使用WINDOW给该条件起一个别名,已达到简化查询的效果。例如,参照之前分位数的查询,我们可以简化如下。
SELECT start_station, duration,
NTILE(4) OVER ntile_window as quartile,
NTILE(100) OVER ntile_window as percentile
FROM biking_records
WINDOW ntile_window AS (PARTITION BY start_station ORDER BY duration)
ORDER BY start_station, duration;



